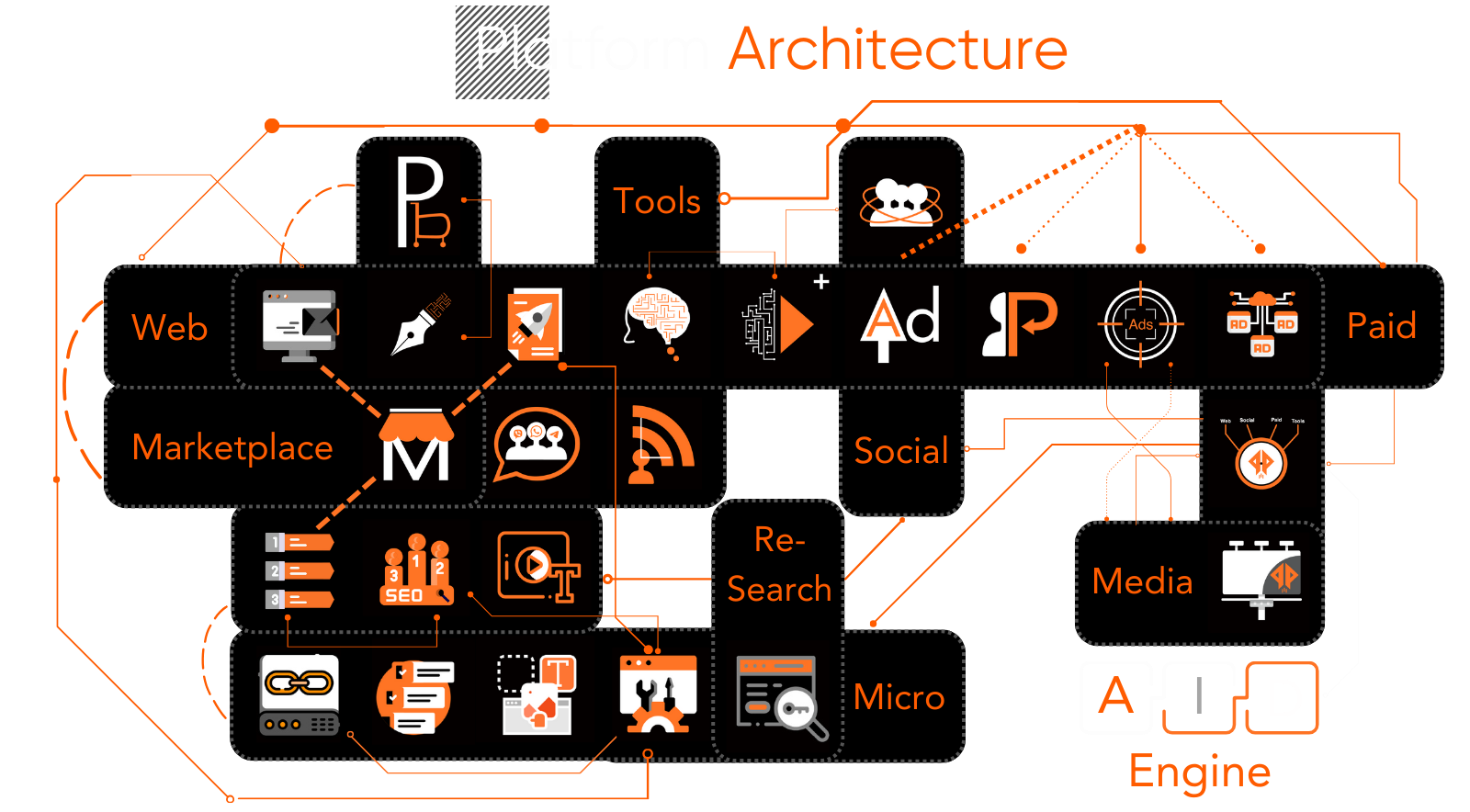
Every Page service either being used from the Web Dashboard, Mobile or API suite gives users access to the entire tools and services.
Pay-As-You-Go Pricing
Page Ads’ pay-as-you-go model optimizes ad spend by charging for essential usage only, eliminating unnecessary subscription-based monthly costs, making it a top choice for cost-effective advertising solutions. With this model, you only pay for what you use, on your Digital Marketing Campaigns.
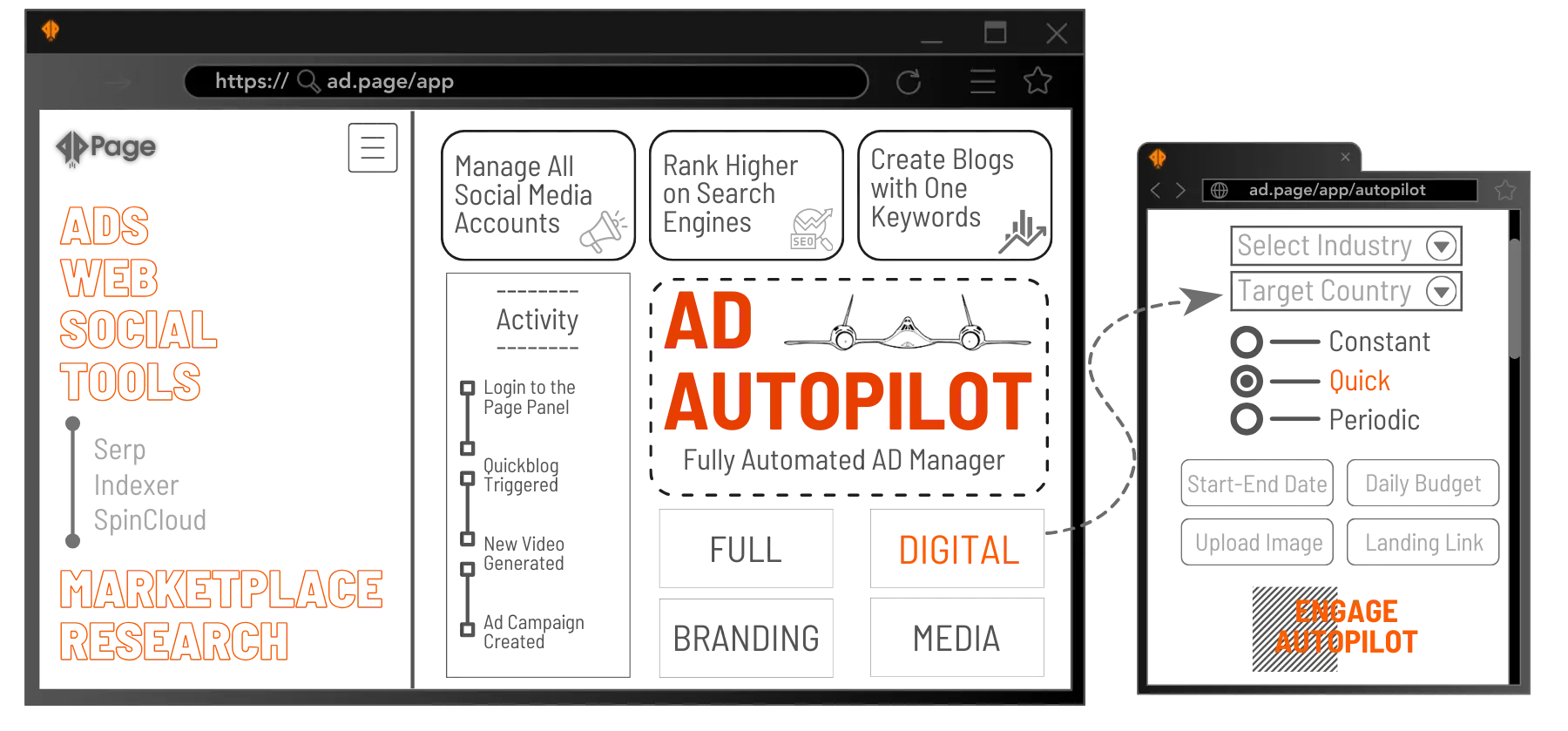
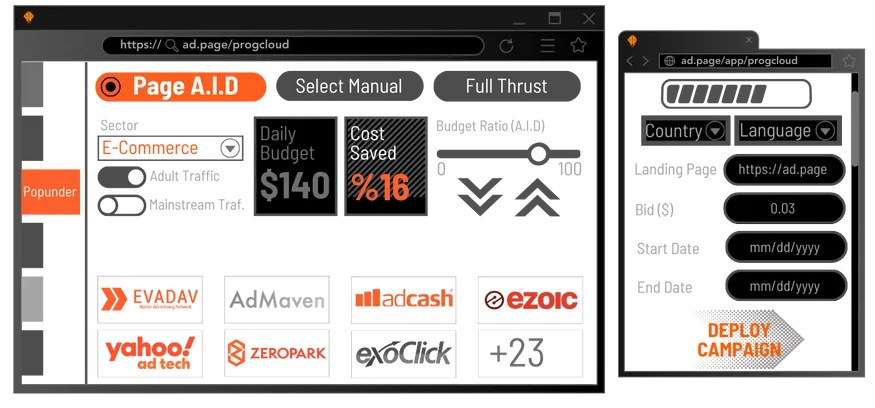
Ad Intelligence Database (A.I.D) is designed to eliminate the guesswork and manual labor traditionally associated with campaign optimization. Users can confidently navigate the advertising landscape, making informed decisions that lead to superior campaign performance and maximized ROI.
Page Mash Ups is a streamlined marketing funnel that connects different channels into one interface, simplifying tasks like video processing, social media management, ad campaigns, and more, to boost efficiency and engagement with just a push of a button.
Sub-services include Page Ads/Monetizre for advertising, Page Social for one-click social media connectivity solutions, and PageSoft for custom integration needs for complex requests.